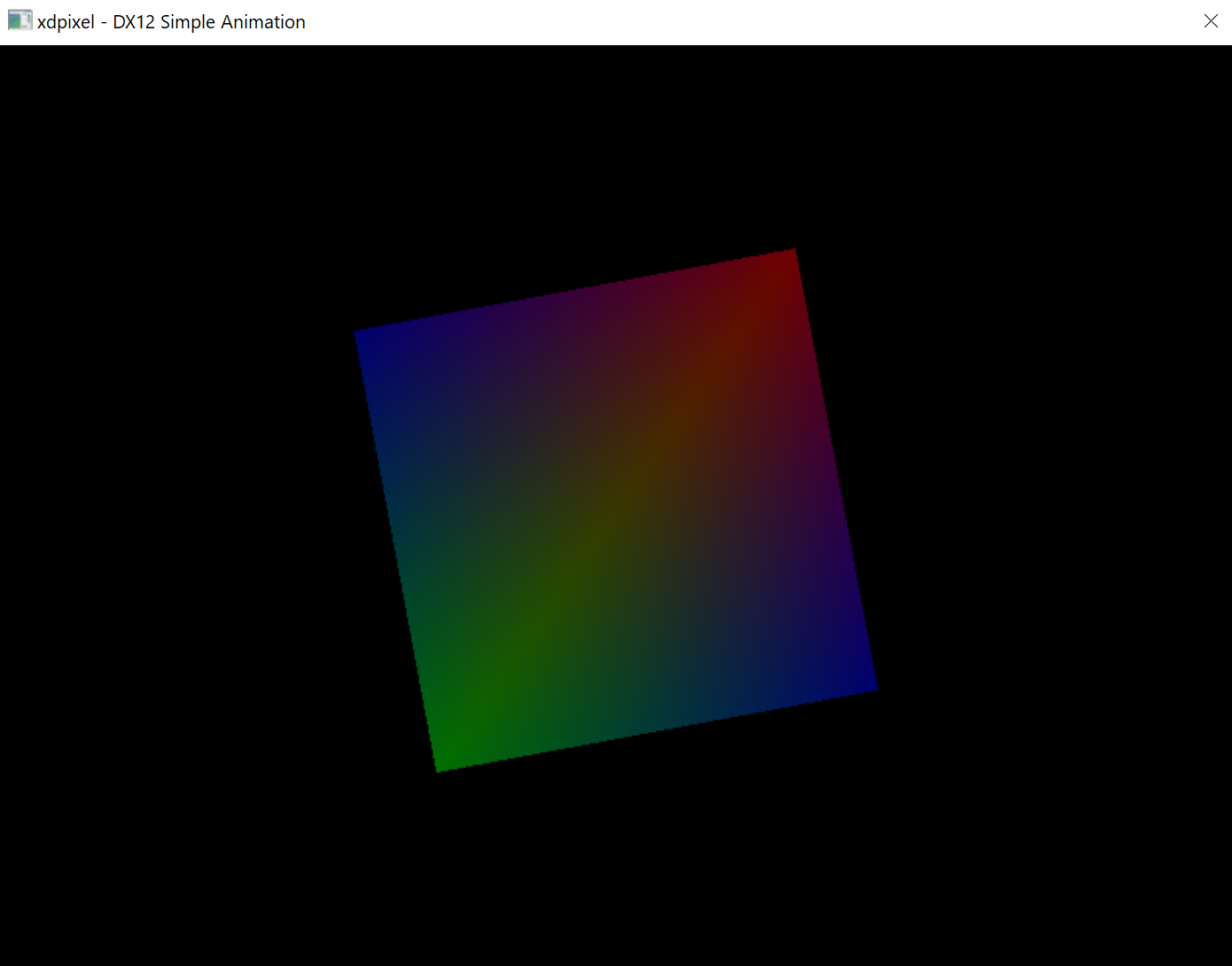
Purpose of the Sample:
This sample builds off of the DirectX 12 “Hello World” sample. It is based heavily on Frank Luna’s implementation from his book “3D Game Programming with DirectX 12”.
This sample demonstrates how to animate an object by uploading the elapsed time to the GPU for use in the vertex and fragment shaders.
CGame.h
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
#ifndef __CGAME__ #define __CGAME__ #include "d3d12.h" #include "dxgi.h" #include "dxgi1_4.h" #include "d3dx12.h" #include "UploadBuffer.h" #include "DirectXMath.h" #include "d3dcompiler.h" #include "external\WRL\ComPTR.h" #include using namespace DirectX; struct ConstantBufferData { XMMATRIX matrixWorld; XMMATRIX matrixView; XMMATRIX matrixProjection; float time; }; typedef std::chrono::high_resolution_clock Time; class CGame { static const int SwapChainCount = 2; ComPtr m_D3D12DebugController; ComPtr m_DXGIFactory; ComPtr m_Dev; ComPtr m_SwapChain; ComPtr m_Fence; ComPtr m_CmdQueue; ComPtr m_CmdAllocator; ComPtr m_GfxCmdList; ComPtr m_CmdAllocatorDraw; ComPtr m_DrawCmdList; ComPtr m_RtvHeap; ComPtr m_DSHeap; ComPtr m_CBVHeap; ComPtr m_SwapChainBuffer[SwapChainCount]; ComPtr m_DepthStencilBuffer; ComPtr m_VertexBufferGPU = NULL; ComPtr m_VertexBufferUploader = NULL; ComPtr m_IndexBufferGPU = NULL; ComPtr m_IndexBufferUploader = NULL; UploadBuffer* m_ObjectCB; ComPtr m_RootSignature; ComPtr m_VSByteCode; ComPtr m_PSByteCode; D3D12_INPUT_ELEMENT_DESC m_InputLayout[2]; ComPtr m_PipelineStateObject; public: void Initialize(void * windowHandle, int width, int height); void Update(); void Render(); void Shutdown(); private: void EnableD3D12DebugMode(); void CreateCommandObjects(); void CreateSwapChain(); void CreateRtvAndDSHeaps(); void CreateBackbufferRtvAndDsv(); void SetupViewportAndScissorRects(); void FlushCommandQueue(); void CreateConstantBuffer(); void CreateRootSignature(); void CreateShadersAndInputLayout(); void CreateVertexBuffer(); void CreateIndexBuffer(); void CreatePSO(); void CreateDrawCommandList(); ID3D12Resource* CurrentBackBuffer() const; D3D12_CPU_DESCRIPTOR_HANDLE CurrentBackBufferView() const; D3D12_CPU_DESCRIPTOR_HANDLE DepthStencilView() const; void* m_WindowHandle; int m_Width; int m_Height; float m_AspectRatio; int m_CurrBackBuffer = 0; int m_RtvDescriptorSize; int m_DsvDescriptorSize; int m_CurrentFence; Time::time_point m_StartTimePoint; }; #endif |
CGame.cpp
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 |
#include "CGame.h" #include #include using namespace std; struct Vertex { float x, y, z, r, g, b, u, v; }; struct Vector { float x, y, z; }; ID3D12Resource* CreateDefaultBuffer(ID3D12Device* dev, ID3D12GraphicsCommandList* cmdLst, const void* initData, UINT64 byteSize, ID3D12Resource* uploadBuffer) { ID3D12Resource* defaultBuffer; dev->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(byteSize), D3D12_RESOURCE_STATE_COMMON, NULL, __uuidof(ID3D12Resource), reinterpret_cast<void**>(&defaultBuffer) ); dev->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(byteSize), D3D12_RESOURCE_STATE_GENERIC_READ, NULL, __uuidof(ID3D12Resource), reinterpret_cast<void**>(&uploadBuffer) ); D3D12_SUBRESOURCE_DATA data = {}; data.pData = initData; data.RowPitch = byteSize; data.SlicePitch = data.RowPitch; cmdLst->ResourceBarrier( 1, &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer, D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST) ); UpdateSubresources<1>(cmdLst, defaultBuffer, uploadBuffer, 0, 0, 1, &data); cmdLst->ResourceBarrier( 1, &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer, D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_GENERIC_READ) ); return defaultBuffer; } void LoadShader(std::string filename, unsigned char*& outShaderSrc, unsigned int& outFileLength) { outShaderSrc = 0; outFileLength = 0; std::ifstream file(filename, std::ios::in | std::ios::binary | std::ios::ate); if (file.is_open()) { outFileLength = (int)file.tellg(); outShaderSrc = new unsigned char[outFileLength]; file.seekg(0, std::ios::beg); file.read(reinterpret_cast<char*>(outShaderSrc), outFileLength); file.close(); } } void CGame::EnableD3D12DebugMode() { HRESULT hr = D3D12GetDebugInterface(__uuidof(ID3D12Debug), reinterpret_cast<void**>(&m_D3D12DebugController)); m_D3D12DebugController->EnableDebugLayer(); } void CGame::CreateCommandObjects() { HRESULT hr = S_OK; D3D12_COMMAND_QUEUE_DESC queueDesc = {}; queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT; queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE; hr = m_Dev->CreateCommandQueue(&queueDesc, __uuidof(ID3D12CommandQueue), reinterpret_cast<void**>(&m_CmdQueue)); hr = m_Dev->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, __uuidof(ID3D12CommandAllocator), reinterpret_cast<void**>(m_CmdAllocator.GetAddressOf())); hr = m_Dev->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, m_CmdAllocator.Get(), NULL, __uuidof(ID3D12CommandList), reinterpret_cast<void**>(m_GfxCmdList.GetAddressOf())); m_GfxCmdList->Close(); } void CGame::CreateDrawCommandList() { HRESULT hr = S_OK; m_Dev->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_BUNDLE, __uuidof(ID3D12CommandAllocator), reinterpret_cast<void**>(m_CmdAllocatorDraw.GetAddressOf())); m_Dev->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_BUNDLE, m_CmdAllocatorDraw.Get(), m_PipelineStateObject.Get(), __uuidof(ID3D12CommandList), reinterpret_cast<void**>(m_DrawCmdList.GetAddressOf())); m_DrawCmdList->SetGraphicsRootSignature(m_RootSignature.Get()); D3D12_VERTEX_BUFFER_VIEW vbView; vbView.BufferLocation = m_VertexBufferGPU->GetGPUVirtualAddress(); vbView.SizeInBytes = 6 * sizeof(Vertex); vbView.StrideInBytes = sizeof(Vertex); m_DrawCmdList->IASetVertexBuffers(0, 1, &vbView); D3D12_INDEX_BUFFER_VIEW ibView; ibView.BufferLocation = m_IndexBufferGPU->GetGPUVirtualAddress(); ibView.SizeInBytes = 6 * sizeof(int); ibView.Format = DXGI_FORMAT_R32_UINT; m_DrawCmdList->IASetIndexBuffer(&ibView); m_DrawCmdList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST); m_DrawCmdList->DrawIndexedInstanced(6, 1, 0, 0, 0); m_DrawCmdList->Close(); } void CGame::CreateSwapChain() { DXGI_SWAP_CHAIN_DESC sd = { 0 }; sd.BufferDesc.Width = m_Width; sd.BufferDesc.Height = m_Height; sd.BufferDesc.Format = DXGI_FORMAT_B8G8R8A8_UNORM; sd.SampleDesc.Count = 1; sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT; sd.BufferCount = SwapChainCount; sd.OutputWindow = (HWND)m_WindowHandle; sd.Windowed = true; sd.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD; sd.Flags = DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH; HRESULT hr = m_DXGIFactory->CreateSwapChain(m_CmdQueue.Get(), &sd, m_SwapChain.GetAddressOf()); m_CurrBackBuffer = 0; } void CGame::CreateRtvAndDSHeaps() { HRESULT hr = S_OK; D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc; rtvHeapDesc.NumDescriptors = SwapChainCount; rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV; rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE; rtvHeapDesc.NodeMask = 0; hr = m_Dev->CreateDescriptorHeap(&rtvHeapDesc, __uuidof(ID3D12DescriptorHeap), reinterpret_cast<void**>(&m_RtvHeap)); D3D12_DESCRIPTOR_HEAP_DESC dsvHeapDesc; dsvHeapDesc.NumDescriptors = 1; dsvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_DSV; dsvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE; dsvHeapDesc.NodeMask = 0; hr = m_Dev->CreateDescriptorHeap(&dsvHeapDesc, __uuidof(ID3D12DescriptorHeap), reinterpret_cast<void**>(&m_DSHeap)); m_RtvDescriptorSize = m_Dev->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV); m_DsvDescriptorSize = m_Dev->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_DSV); } void CGame::CreateBackbufferRtvAndDsv() { FlushCommandQueue(); m_GfxCmdList->Reset(m_CmdAllocator.Get(), NULL); m_SwapChain->ResizeBuffers( SwapChainCount, m_Width, m_Height, DXGI_FORMAT_B8G8R8A8_UNORM, DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH); m_CurrBackBuffer = 0; CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(m_RtvHeap->GetCPUDescriptorHandleForHeapStart()); for (int i = 0; i < SwapChainCount; ++i) { m_SwapChain->GetBuffer(i, __uuidof(ID3D12Resource), reinterpret_cast<void**>(&m_SwapChainBuffer[i])); m_Dev->CreateRenderTargetView(m_SwapChainBuffer[i].Get(), NULL, rtvHeapHandle); rtvHeapHandle.Offset(1, m_RtvDescriptorSize); } D3D12_RESOURCE_DESC depthStencilDesc = { 0 }; depthStencilDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; depthStencilDesc.Width = m_Width; depthStencilDesc.Height = m_Height; depthStencilDesc.DepthOrArraySize = 1; depthStencilDesc.MipLevels = 1; depthStencilDesc.Format = DXGI_FORMAT_D24_UNORM_S8_UINT; depthStencilDesc.SampleDesc.Count = 1; depthStencilDesc.SampleDesc.Quality = 0; depthStencilDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL; D3D12_CLEAR_VALUE optClear; optClear.Format = DXGI_FORMAT_D24_UNORM_S8_UINT; optClear.DepthStencil.Depth = 1.0f; optClear.DepthStencil.Stencil = 0; HRESULT hr = S_OK; hr = m_Dev->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &depthStencilDesc, D3D12_RESOURCE_STATE_COMMON, &optClear, __uuidof(ID3D12Resource), reinterpret_cast<void**>(&m_DepthStencilBuffer)); m_Dev->CreateDepthStencilView(m_DepthStencilBuffer.Get(), NULL, DepthStencilView()); m_GfxCmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_DepthStencilBuffer.Get(), D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_DEPTH_WRITE)); hr = m_GfxCmdList->Close(); ID3D12CommandList* cmdLists[1] = { m_GfxCmdList.Get() }; m_CmdQueue->ExecuteCommandLists(1, cmdLists); FlushCommandQueue(); } void CGame::SetupViewportAndScissorRects() { D3D12_VIEWPORT vp; vp.TopLeftX = 0.0f; vp.TopLeftY = 0.0f; vp.Width = static_cast(m_Width); vp.Height = static_cast(m_Height); vp.MinDepth = 0.0f; vp.MaxDepth = 1.0f; m_GfxCmdList->RSSetViewports(1, &vp); D3D12_RECT scissorRect = { 0,0, m_Width, m_Height }; m_GfxCmdList->RSSetScissorRects(1, &scissorRect); } ID3D12Resource* CGame::CurrentBackBuffer() const { return m_SwapChainBuffer[m_CurrBackBuffer].Get(); } D3D12_CPU_DESCRIPTOR_HANDLE CGame::CurrentBackBufferView() const { return CD3DX12_CPU_DESCRIPTOR_HANDLE( m_RtvHeap->GetCPUDescriptorHandleForHeapStart(), m_CurrBackBuffer, m_RtvDescriptorSize); } D3D12_CPU_DESCRIPTOR_HANDLE CGame::DepthStencilView() const { return m_DSHeap->GetCPUDescriptorHandleForHeapStart(); } void CGame::FlushCommandQueue() { // Advance the fence value to mark commands up to this fence point. m_CurrentFence++; // Add an instruction to the command queue to set a new fence point. Because we // are on the GPU timeline, the new fence point won't be set until the GPU finishes // processing all the commands prior to this Signal(). m_CmdQueue->Signal(m_Fence.Get(), m_CurrentFence); // Wait until the GPU has completed commands up to this fence point. if (m_Fence->GetCompletedValue() < m_CurrentFence) { HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS); // Fire event when GPU hits current fence. m_Fence->SetEventOnCompletion(m_CurrentFence, eventHandle); // Wait until the GPU hits current fence event is fired. WaitForSingleObject(eventHandle, INFINITE); CloseHandle(eventHandle); } } void CGame::CreateConstantBuffer() { HRESULT hr = S_OK; D3D12_DESCRIPTOR_HEAP_DESC heapDesc; heapDesc.NumDescriptors = 1; heapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV; heapDesc.NodeMask = 0; heapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE; hr = m_Dev->CreateDescriptorHeap(&heapDesc, __uuidof(ID3D12DescriptorHeap), reinterpret_cast<void**>(&m_CBVHeap)); m_ObjectCB = new UploadBuffer(m_Dev.Get(), 1, true); UINT objCBByteSize = CalcConstantBufferByteSize(sizeof(ConstantBufferData)); D3D12_GPU_VIRTUAL_ADDRESS cbAddress = m_ObjectCB->Resource()->GetGPUVirtualAddress(); D3D12_CONSTANT_BUFFER_VIEW_DESC cbDesc; cbDesc.BufferLocation = cbAddress; cbDesc.SizeInBytes = objCBByteSize; m_Dev->CreateConstantBufferView(&cbDesc, m_CBVHeap->GetCPUDescriptorHandleForHeapStart()); } void CGame::CreateRootSignature() { HRESULT hr = S_OK; CD3DX12_ROOT_PARAMETER slotRootParameter[1]; CD3DX12_DESCRIPTOR_RANGE cbvTable; cbvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 0); slotRootParameter[0].InitAsDescriptorTable(1, &cbvTable); CD3DX12_ROOT_SIGNATURE_DESC rsDesc(1, slotRootParameter, 0, NULL, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT); ID3DBlob* serializedRootSigBlob = NULL; ID3DBlob* errorBlob = NULL; hr = D3D12SerializeRootSignature(&rsDesc, D3D_ROOT_SIGNATURE_VERSION_1, &serializedRootSigBlob, &errorBlob); hr = m_Dev->CreateRootSignature(0, serializedRootSigBlob->GetBufferPointer(), serializedRootSigBlob->GetBufferSize(), __uuidof(ID3D12RootSignature), reinterpret_cast<void**>(&m_RootSignature)); } void CGame::CreateShadersAndInputLayout() { HRESULT hr = S_OK; hr = D3DCompileFromFile(L"Assets/VertexShader.hlsl", NULL, NULL, "main", "vs_5_0", 0, 0, m_VSByteCode.GetAddressOf(), NULL); hr = D3DCompileFromFile(L"Assets/PixelShader.hlsl", NULL, NULL, "main", "ps_5_0", 0, 0, m_PSByteCode.GetAddressOf(), NULL); m_InputLayout[0] = D3D12_INPUT_ELEMENT_DESC( { "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 } ); m_InputLayout[1] = D3D12_INPUT_ELEMENT_DESC( { "COLOR", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, D3D12_APPEND_ALIGNED_ELEMENT, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 } ); } void CGame::CreateVertexBuffer() { m_GfxCmdList->Reset(m_CmdAllocator.Get(), NULL); Vertex triangle[] = { { -0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f }, { 0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f }, { -0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f }, { -0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f }, { 0.5f, 0.5f, 0.0f, 0.0f, 0.0f, 1.0f }, { 0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f }, }; m_VertexBufferGPU = CreateDefaultBuffer(m_Dev.Get(), m_GfxCmdList.Get(), triangle, 6 * sizeof(Vertex), m_VertexBufferUploader.Get()); HRESULT hr = m_GfxCmdList->Close(); ID3D12CommandList* cmdLists[1] = { m_GfxCmdList.Get() }; m_CmdQueue->ExecuteCommandLists(1, cmdLists); FlushCommandQueue(); } void CGame::CreateIndexBuffer() { m_GfxCmdList->Reset(m_CmdAllocator.Get(), NULL); int indices[] = { 0, 1, 2, 0, 4, 1 }; m_IndexBufferGPU = CreateDefaultBuffer(m_Dev.Get(), m_GfxCmdList.Get(), indices, sizeof(int) * 6, m_IndexBufferUploader.Get()); HRESULT hr = m_GfxCmdList->Close(); ID3D12CommandList* cmdLists[1] = { m_GfxCmdList.Get() }; m_CmdQueue->ExecuteCommandLists(1, cmdLists); FlushCommandQueue(); } void CGame::CreatePSO() { HRESULT hr = S_OK; D3D12_GRAPHICS_PIPELINE_STATE_DESC desc; ZeroMemory(&desc, sizeof(D3D12_GRAPHICS_PIPELINE_STATE_DESC)); desc.InputLayout = { m_InputLayout, 2 }; desc.pRootSignature = m_RootSignature.Get(); desc.VS = { reinterpret_cast<BYTE*>(m_VSByteCode->GetBufferPointer()), m_VSByteCode->GetBufferSize() }; desc.PS = { reinterpret_cast<BYTE*>(m_PSByteCode->GetBufferPointer()), m_PSByteCode->GetBufferSize() }; desc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT); desc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT); desc.DepthStencilState = CD3DX12_DEPTH_STENCIL_DESC(D3D12_DEFAULT); desc.SampleMask = UINT_MAX; desc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE; desc.NumRenderTargets = 1; desc.RTVFormats[0] = DXGI_FORMAT_B8G8R8A8_UNORM; desc.SampleDesc.Count = 1; desc.SampleDesc.Quality = 0; desc.DSVFormat = DXGI_FORMAT_D24_UNORM_S8_UINT; hr = m_Dev->CreateGraphicsPipelineState(&desc, __uuidof(ID3D12PipelineState), reinterpret_cast<void**>(&m_PipelineStateObject)); } void CGame::Initialize(void * windowHandle, int width, int height) { m_WindowHandle = static_cast<int*>(windowHandle); m_Width = width; m_Height = height; m_AspectRatio = (float)width / (float)height; HRESULT hr = S_OK; EnableD3D12DebugMode(); hr = CreateDXGIFactory1(__uuidof(IDXGIFactory4), reinterpret_cast<void**>(&m_DXGIFactory)); hr = D3D12CreateDevice(NULL, D3D_FEATURE_LEVEL_12_1, __uuidof(ID3D12Device), reinterpret_cast<void**>(&m_Dev)); m_CurrentFence = 0; hr = m_Dev->CreateFence(0, D3D12_FENCE_FLAG_NONE, __uuidof(ID3D12Fence), reinterpret_cast<void**>(&m_Fence)); CreateCommandObjects(); CreateSwapChain(); CreateRtvAndDSHeaps(); CreateBackbufferRtvAndDsv(); CreateConstantBuffer(); CreateRootSignature(); CreateShadersAndInputLayout(); CreateVertexBuffer(); CreateIndexBuffer(); CreatePSO(); CreateDrawCommandList(); m_StartTimePoint = Time::now(); } void CGame::Shutdown() { FlushCommandQueue(); } void CGame::Update() { chrono::duration deltaTime = Time::now() - m_StartTimePoint; const float elapsedTimeInSeconds = deltaTime.count(); XMMATRIX matWorld = XMMatrixRotationY(3.14159f) * XMMatrixRotationZ(3.14159f * elapsedTimeInSeconds); XMVECTOR vecCamPos = XMVectorSet(0.0f, 0.0f, 2.5f, 0); XMVECTOR vecCamLookAt = XMVectorSet(0, 0, 0, 0); XMVECTOR vecCamUp = XMVectorSet(0, 1, 0, 0); XMMATRIX matView = XMMatrixLookAtLH(vecCamPos, vecCamLookAt, vecCamUp); XMMATRIX matProjection = XMMatrixPerspectiveFovLH( XMConvertToRadians(45), m_AspectRatio, 1, 100); XMMATRIX matMVP = matWorld * matView * matProjection; ConstantBufferData constantBufferData; constantBufferData.matrixWorld = matWorld; constantBufferData.matrixView = matView; constantBufferData.matrixProjection = matProjection; constantBufferData.time = elapsedTimeInSeconds; m_ObjectCB->CopyData(0, constantBufferData); } void CGame::Render() { HRESULT hr = S_OK; hr = m_CmdAllocator->Reset(); hr = m_GfxCmdList->Reset(m_CmdAllocator.Get(), m_PipelineStateObject.Get()); m_GfxCmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_PRESENT, D3D12_RESOURCE_STATE_RENDER_TARGET)); SetupViewportAndScissorRects(); float color[4] = { 0.0f, 0.0f, 0.0f, 1.0f }; m_GfxCmdList->ClearRenderTargetView(CurrentBackBufferView(), color, 0, NULL); m_GfxCmdList->ClearDepthStencilView(DepthStencilView(), D3D12_CLEAR_FLAG_DEPTH | D3D12_CLEAR_FLAG_STENCIL, 1.0f, 0, 0, NULL); m_GfxCmdList->OMSetRenderTargets(1, &CurrentBackBufferView(), true, &DepthStencilView()); m_GfxCmdList->SetGraphicsRootSignature(m_RootSignature.Get()); ID3D12DescriptorHeap* descHeaps = { m_CBVHeap.Get() }; m_GfxCmdList->SetDescriptorHeaps(1, &descHeaps); m_GfxCmdList->SetGraphicsRootDescriptorTable(0, m_CBVHeap->GetGPUDescriptorHandleForHeapStart()); m_GfxCmdList->ExecuteBundle(m_DrawCmdList.Get()); m_GfxCmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(CurrentBackBuffer(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT)); m_GfxCmdList->Close(); ID3D12CommandList* cmdLsts[] = { m_GfxCmdList.Get() }; m_CmdQueue->ExecuteCommandLists(1, cmdLsts); m_SwapChain->Present(0, 0); m_CurrBackBuffer = (m_CurrBackBuffer + 1) % SwapChainCount; FlushCommandQueue(); } |
UploadBuffer.h
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
#pragma once #include "d3d12.h" static UINT CalcConstantBufferByteSize(UINT byteSize) { // Constant buffers must be a multiple of the minimum hardware // allocation size (usually 256 bytes). So round up to nearest // multiple of 256. We do this by adding 255 and then masking off // the lower 2 bytes which store all bits < 256. // Example: Suppose byteSize = 300. // (300 + 255) & ~255 // 555 & ~255 // 0x022B & ~0x00ff // 0x022B & 0xff00 // 0x0200 // 512 return (byteSize + 255) & ~255; } template class UploadBuffer { public: UploadBuffer(ID3D12Device* device, UINT elementCount, bool isConstantBuffer) : mIsConstantBuffer(isConstantBuffer) { mElementByteSize = sizeof(T); // Constant buffer elements need to be multiples of 256 bytes. // This is because the hardware can only view constant data // at m*256 byte offsets and of n*256 byte lengths. // typedef struct D3D12_CONSTANT_BUFFER_VIEW_DESC { // UINT64 OffsetInBytes; // multiple of 256 // UINT SizeInBytes; // multiple of 256 // } D3D12_CONSTANT_BUFFER_VIEW_DESC; if(isConstantBuffer) mElementByteSize = CalcConstantBufferByteSize(sizeof(T)); device->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(mElementByteSize*elementCount), D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&mUploadBuffer)); mUploadBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mMappedData)); // We do not need to unmap until we are done with the resource. However, we must not write to // the resource while it is in use by the GPU (so we must use synchronization techniques). } UploadBuffer(const UploadBuffer& rhs) = delete; UploadBuffer& operator=(const UploadBuffer& rhs) = delete; ~UploadBuffer() { if(mUploadBuffer != nullptr) mUploadBuffer->Unmap(0, nullptr); mMappedData = nullptr; } ID3D12Resource* Resource()const { return mUploadBuffer; } void CopyData(int elementIndex, const T& data) { memcpy(&mMappedData[elementIndex*mElementByteSize], &data, sizeof(T)); } private: ID3D12Resource* mUploadBuffer; BYTE* mMappedData = nullptr; UINT mElementByteSize = 0; bool mIsConstantBuffer = false; }; |
VertexShader.hlsl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
cbuffer ConstantBufferData { float4x4 matrixWorld; float4x4 matrixView; float4x4 matrixProjection; float time; } struct v2f { float4 position : SV_POSITION; float4 color : COLOR0; }; v2f main( float4 pos : POSITION, float4 color : COLOR ) { v2f o; float4 worldPos = mul(matrixWorld, pos); float4x4 matVP = mul(matrixProjection, matrixView); o.position = mul(matVP, worldPos); float4 finalColor = color * (sin(time) * 0.5 + 0.5); o.color = finalColor; return o; } |
PixelShader.hlsl
|
1 2 3 4 5 6 7 8 9 10 |
struct v2f { float4 position : SV_POSITION; float4 color : COLOR; }; float4 main(v2f i) : SV_TARGET { return float4(i.color.rgb, 1.0); } |