Overview
In this article, I want to teach you how to write GPU Shader friendly code that avoids the performance costs associated with branching.
What Do You Mean By “Branching”?
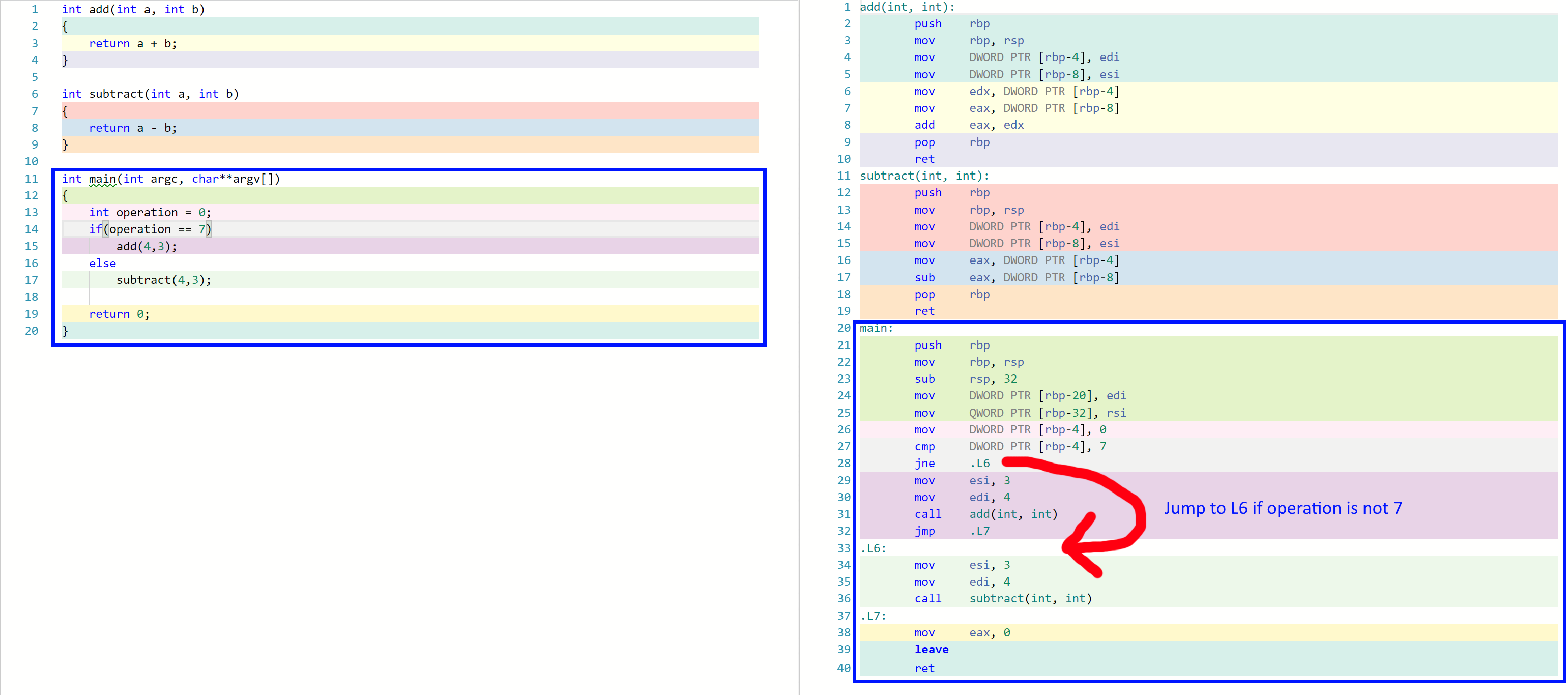
You are branching anytime you use an explicit if/then. When your compiler encounters a conditional, it has a decision to make. There are at least two places the CPU could go. So it must decide which code path to take. The following example shows an example executed on the CPU in assembly. If the operation variable is set to the magic number “7” then we add. Otherwise, we will subtract.
Why Should I Avoid Branching?
Most computers try to pipeline as much work as possible to keep the CPU busy. The assembly instructions are executed in order and a CPU will try to execute as many commands as it can on as many CPU cores as it can. Lets think of a simple example. Imagine we are in the Twilight Zone and you are the most efficient programmer in the world! You managed to write a video game in two single lines of code! A CPU will try to execute those two glorious commands, one on each CPU core if it can, in parallel. This allows the computer to execute code more efficiently. However, when you branch, the computer may have spent time preparing the result of code that it was never meant to execute. This results in wasted processor time which ultimately impacts the responsiveness of your game or application.
CPU side branch misprediction will typically result in at least 40 missed cycles. – Charles Sanglimsuwan (Unity Developer Relations Engineer)
Fortunately, modern CPU processors are incredibly fast and really great at branch prediction therefore branch misses are mostly a non-issue. However, on GPUs, it still is a performance issue. Due to the massive number of computations GPUs are trying to solve in parallel, most GPUs don’t support branch prediction.
Why is Branching a Performance Issue on the GPU?
GPUs like to do A LOT of work in parallel to generate beautiful pictures!

GPUs are well designed to solve problems which involve varying inputs that run through a single filter (I.E. shader program) in order to compute many many many unique results. That is why rendering is such a great use of GPUs (Graphic processor units). You run a bunch of unique vertices with various attributes like position, normals, texture coordinates, etc through a few shader programs that output many many many unique pixel colors to display on your screen. For example, if your display was a common HD resolution like 1080×960, your GPU would compute 1080×960 = 1,036,800 unique pixel color values given a set of input! That is a lot of computational output! Now imagine you are running a game in HD at 1080×960. Your game will try to render 60 unique images or frames per second. Therefore your GPU will need to compute over 1080x960x60 unique pixel color values over the duration of a single second! That results in 62,208,000 unique pixel value computations in a single second!
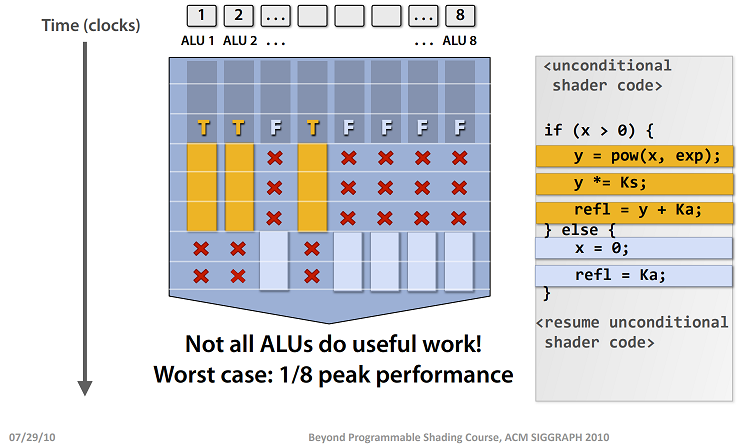
As of this writing, Nvidia’s most advanced GPU is the GeForce RTX 2080 Ti. It sports 4,352 cuda cores which is far more than Intel’s most advance CPU processor, the i9-7980XE, which sports a whopping 18 cores. Considerable difference right? While GPUs have many processing cores, when compared to a modern CPU, they certainly don’t have over a million of them. Atleast not yet! Graphics cards can physically only be so big and cost so much to make. Therefore the GPU tries to make certain assumptions about the kinds of problems that it will solve. GPUs take considerable advantage of SIMD. SIMD stands for Single Instruction Multiple Data. SIMD allows you to run calculations on multiple inputs in parallel. SIMD often expects input and output to live in contiguous blocks of memory. Therefore SIMD operations can help reduce expensive memory loads and stores by loading inputs and storing results in a single load/store operation as opposed to loading each input and storing each result individually. SIMD usage can provide the nice side effect of helping your application’s design have better memory cache coherency by requiring these kind of strict memory layouts. SIMD can be used both on the CPU and GPU. Take a look here for examples on using SIMD on the CPU. Unlike CPU programs, you will almost always use SIMD in GPU programs. GPUs often have many ALUs per core to take maximum advantage of SIMD. An ALU is short for Arithmetic Logic Unit. An ALU is responsible for executing mathematical commands. For example, it will take a command like “add 4, 3” and compute the result 7. So if you have 8 ALUs in a single core, you can run 8 calculations in parallel at the same time. That means that if a single GPU core has 8 ALUs then a single GPU core could compute the value of 8 pixels at the same time in parallel! However, what happens if you have dynamic branching in a shader stage? Well, the core will have to execute all the code paths and discard those code paths that don’t ultimately satisfy the condition. This means that the ALUs will waste time doing work that will never be used. That means it will take longer for your image to be rendered.
Use Case:
At Unity, we use a stereo shader for ensuring both eyes are correctly rendered to. Anything rendered to the left eye will show up as green and anything rendered to the right eye will show up as red. Below we are rendering a single sphere which uses the stereo shader and is rendered to both eyes.

A naive approach to this would be to simply use a conditional based on the unity_StereoEyeIndex variable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
Shader "XR/StereoEyeIndexColor" { Properties { _LeftEyeColor("Left Eye Color", COLOR) = (0,1,0,1) _RightEyeColor("Right Eye Color", COLOR) = (1,0,0,1) } SubShader { Tags { "RenderType" = "Opaque" } Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag float4 _LeftEyeColor; float4 _RightEyeColor; #include "UnityCG.cginc" struct appdata { float4 vertex : POSITION; UNITY_VERTEX_INPUT_INSTANCE_ID }; struct v2f { float4 vertex : SV_POSITION; UNITY_VERTEX_OUTPUT_STEREO }; v2f vert (appdata v) { v2f o; UNITY_SETUP_INSTANCE_ID(v); UNITY_INITIALIZE_OUTPUT(v2f, o); UNITY_INITIALIZE_VERTEX_OUTPUT_STEREO(o); o.vertex = UnityObjectToClipPos(v.vertex); return o; } fixed4 frag (v2f i) : SV_Target { UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i); if(unity_StereoEyeIndex == 0) { return _LeftEyeColor; } return _RightEyeColor; } ENDCG } } } |
The fragment shader assembly output looks like so,
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Shader hash 084f3be2-e9e6b34f-66f52d0a-1b95fab0 ps_4_0 dcl_constantbuffer cb0[2], immediateIndexed dcl_input_ps_siv v1.x, rendertarget_array_index dcl_output o0.xyzw 0: if_z v1.x 1: mov o0.xyzw, cb0[0].xyzw 2: ret 3: endif 4: mov o0.xyzw, cb0[1].xyzw 5: ret |
Notice the branch starting on line 0? The core assigned to the fragment shader stage will have all of its ALUs execute the result of both conditions. However, the result of the condition that wasn’t satisfied will be discarded. In that case, some of the ALUs will have done work that was wasted. We just made several ALUs very sad and now they are questioning their very reason for being. Don’t give the poor little ALUs busy work. You don’t like your time being wasted either right? Keep the ALUs busy doing work that is useful!
If we can factor out the conditional, we can ensure that any wasted work is mitigated and thus make our ALUs more productive and happy! Take a look at how the fragment shader is implemented in the following example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
Shader "XR/StereoEyeIndexColor" { Properties { _LeftEyeColor("Left Eye Color", COLOR) = (0,1,0,1) _RightEyeColor("Right Eye Color", COLOR) = (1,0,0,1) } SubShader { Tags { "RenderType" = "Opaque" } Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag float4 _LeftEyeColor; float4 _RightEyeColor; #include "UnityCG.cginc" struct appdata { float4 vertex : POSITION; UNITY_VERTEX_INPUT_INSTANCE_ID }; struct v2f { float4 vertex : SV_POSITION; UNITY_VERTEX_OUTPUT_STEREO }; v2f vert (appdata v) { v2f o; UNITY_SETUP_INSTANCE_ID(v); UNITY_INITIALIZE_OUTPUT(v2f, o); UNITY_INITIALIZE_VERTEX_OUTPUT_STEREO(o); o.vertex = UnityObjectToClipPos(v.vertex); return o; } fixed4 frag (v2f i) : SV_Target { UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i); return lerp(_LeftEyeColor, _RightEyeColor, unity_StereoEyeIndex); } ENDCG } } } |
Notice that there is no explicit conditional. Lets see what the HLSL assembly output is.
|
1 2 3 4 5 6 7 8 9 10 11 |
Shader hash 7f0a4d98-21be8f11-77007603-2899b3a0 ps_4_0 dcl_constantbuffer cb0[2], immediateIndexed dcl_input_ps_siv v1.x, rendertarget_array_index dcl_output o0.xyzw dcl_temps 2 0: utof r0.x, v1.x 1: add r1.xyzw, -cb0[0].xyzw, cb0[1].xyzw 2: mad o0.xyzw, r0.xxxx, r1.xyzw, cb0[0].xyzw 3: ret |
Look at that! No branching!
We are now using lerp instead of an explicit conditional. Lerp performs a linear interpolation between two values. Lerp is essentially the following
|
1 2 3 4 |
float lerp( float a, float b, float t) { return (1.0f-t)*a + t*b; } |
As you can see in the assembly output, lerp is translated into a multiply and a couple of adds which is much better than a branch. Basically, you feed a lerp function two arbitrary values and pass in a third parameter which is sometimes called the “t value”. The t value is generally a number somewhere between 0.0 and 1.0 which is a convenient number space to work in. If the t value is 0.0 then the result will be a. If the t value is 1, then the result will be b. If the t value is anything in between 0.0 and 1.0, the result will linearly be somewhere between a and b as well. In our case, we know that the unity_StereoEyeIndex will be either 0 or 1 for the left or right eye respectively. So this works out nicely and allows us to avoid an explicit branch.
What Are Some Other Ways to Avoid Branching?
Basically what you want to do is convert conditions into mathematical equations. I am going to introduce you to some HLSL hardware accelerated functions that can help you do just that. There are more that you could use but these will start you along your journey.
- step(y,x)
- 1 if the x parameter is greater than or equal to the y parameter; otherwise, 0.
- lerp(x,y,t)
- The result of the linear interpolation.
- min(x,y)
- The x or y parameter, whichever is the smallest value.
- max(x,y)
- The x or y parameter, whichever is the largest value.
Lerp is handy when you want to return two different arbitrary values based on some condition.
Step is handy for Boolean operations. If you have a case where you either want something to be returned only if something if true. For example, lets say I have a function like the following.
|
1 2 3 4 5 6 7 8 9 10 |
// The enable parameter should be either 0 or 1 // If enable is 1, then the color blue is returned. Otherwise the color black is returned. // If you add the result of AddBlueTint to your final color and black is returned, // your original color will remain unchanged. float3 AddBlueTint( float enable ) { return step(0.5, enable) * float3(0,0,1); } float3 finalColor = someColor + AddBlueTint(1.0); |
We can even modify the stereo shader to use step instead of lerp like so,
|
1 2 3 4 5 |
fixed4 frag (v2f i) : SV_Target { UNITY_SETUP_STEREO_EYE_INDEX_POST_VERTEX(i); return step(unity_StereoEyeIndex, 0.5) *_LeftEyeColor + step(0.5, unity_StereoEyeIndex) * _RightEyeColor; } |
The HLSL assembly would then look like
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Shader hash e56cb1bf-ce5441de-72c92b9d-336cc956 ps_4_0 dcl_constantbuffer cb0[2], immediateIndexed dcl_input_ps_siv v1.x, rendertarget_array_index dcl_output o0.xyzw dcl_temps 2 0: utof r0.x, v1.x 1: ge r0.y, r0.x, l(0.500000) 2: ge r0.x, l(0.500000), r0.x 3: and r0.xy, r0.xyxx, l(1.000000, 1.000000, 0.000000, 0.000000) 4: mul r1.xyzw, r0.yyyy, cb0[1].xyzw 5: mad o0.xyzw, r0.xxxx, cb0[0].xyzw, r1.xyzw 6: ret |
Again, no branches! The SIMD shader assembly command “ge” is not a branch. It is essentially what HLSL step command is translated to in shader assembly. ge is a command that calculates if an input is greater than or equal to another input value and returns the values 1 or 0 depending on the result. You can use multiple step functions to return a result based on if the input values are within some range. This is typically called a “pulse function”. For example you can factor the following conditional
|
1 2 3 4 |
if(value >= 0.5 && value <= 1.0) { return float3(0,0,1); } |
by using a pulse function composed of two step functions.
|
1 2 3 4 5 6 |
float pulse(float value, float minValue, float maxValue) { return step(minValue,value) - step(maxValue, value); } float3 finalColor = float3(0,0,1) * pulse(0.4, 0.1, 0.5); |
You can play around with the pulse function here.
You can use min/max for choosing the bigger or smaller of two values. Keep in mind that all of these intrinsic functions are either hardware accelerated functions or will be translated into hardware accelerated functions like in the case of lerp. That means that these methods are or are translated into methods which are logic circuits baked onto the silicon of your graphics card.
For more ways to factor out conditionals, check out the following article by Orange Duck. For more information on GPU cores and how they work, take a look at the following UC Davis presentation.
That’s all for now folks! Go create something!